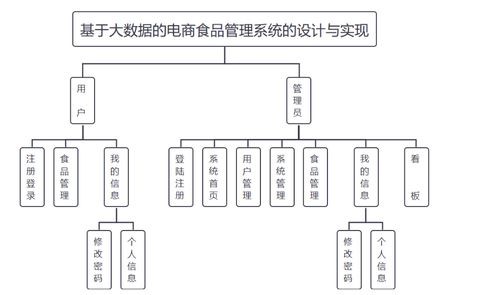
系统概述
随着电子商务的迅猛发展,海量商品与用户行为数据对个性化推荐提出了更高要求。本文设计并实现了一个基于SpringBoot框架、整合大数据处理技术与协同过滤推荐算法的电商商品推荐系统。该系统旨在从海量用户行为数据中挖掘潜在兴趣,为用户提供精准、个性化的商品推荐,有效提升用户体验与平台转化率。
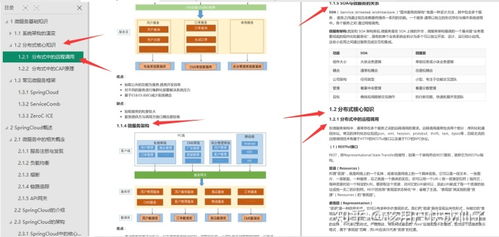
一、系统核心架构设计
1.1 技术栈选型
- 后端框架:SpringBoot 2.x,提供快速开发、自动配置与微服务支持。
- 数据处理与存储:
- 大数据组件:Hadoop HDFS用于原始数据存储,Spark MLlib用于分布式协同过滤模型训练。
- 数据库:MySQL存储用户、商品等结构化数据;Redis缓存热门推荐结果与用户会话。
- 推荐算法:基于用户的协同过滤(User-CF)与基于物品的协同过滤(Item-CF)混合模型,结合用户历史行为(浏览、收藏、购买)计算相似度。
- 系统集成:通过RESTful API提供推荐服务,支持与前端商城系统、用户行为采集系统无缝集成。
1.2 系统模块划分
- 数据采集与预处理模块:收集用户行为日志,清洗并转换为评分矩阵。
- 离线推荐模块:基于Spark定期训练协同过滤模型,生成用户-商品推荐列表并存入Redis。
- 实时推荐模块:根据用户最近行为(如实时点击)进行局部相似度计算,对离线结果进行微调。
- 推荐服务模块:SpringBoot构建的API服务,根据用户ID返回个性化推荐列表。
- 系统管理模块:提供算法参数配置、推荐效果监控(如点击率、转化率)等功能。
二、关键实现细节
2.1 协同过滤算法实现
系统采用混合协同过滤策略以平衡推荐精度与实时性:
- 离线阶段:使用Spark ALS(交替最小二乘法)训练矩阵分解模型,处理隐式反馈数据(将浏览时长、购买次数转换为隐式评分)。核心代码片段(Scala示例):
`scala
val als = new ALS()
.setRank(10)
.setIterations(10)
.setImplicitPrefs(true)
val model = als.fit(ratingsRDD)
val recommendations = model.recommendProductsForUsers(10)
`
- 在线阶段:基于Item-CF计算实时相似度,当用户对商品A产生行为时,快速检索与A最相似的商品集合。
2.2 SpringBoot服务集成
推荐服务以独立微服务形式部署,通过SpringBoot暴露REST接口:`java
@RestController
@RequestMapping("/recommend")
public class RecommendController {
@Autowired
private RecommendService recommendService;
@GetMapping("/user/{userId}")
public List
return recommendService.getHybridRecommendations(userId);
}
}`
服务内部集成Redis缓存,查询优先级:实时推荐 > 离线缓存 > 默认热门商品。
三、系统部署与运维讲解
3.1 环境准备
- 基础环境:CentOS 7+,JDK 1.8+,Maven 3.6+。
- 大数据集群(可选,小数据量可单机模拟):
- Hadoop 3.x 与 Spark 3.x 集群,至少1个Master节点和2个Worker节点。
- 配置SSH免密登录与环境变量。
- 数据库:MySQL 5.7+,Redis 5.x。
3.2 部署步骤
- 源码(lw)结构说明:
src/main/java:SpringBoot服务源码,含控制器、服务层、工具类。
src/main/resources:配置文件(application.yml、Spark配置等)。
scripts/:部署脚本,包括Spark任务提交脚本、数据导入脚本。
sql/:数据库初始化DDL。
2. 部署流程:
a. 导入SQL文件,初始化用户、商品表。
b. 修改配置文件中的数据库连接、Redis地址及Spark Master地址。
c. 使用Maven打包:mvn clean package -DskipTests。
d. 上传Jar包至服务器,运行:java -jar recommend-system.jar。
e. 提交Spark离线任务:spark-submit --class com.etl.OfflineRecommender spark-job.jar。
3. 系统集成服务调用:
商城系统通过HTTP调用推荐接口,示例请求:
`
GET http://推荐服务IP:8080/recommend/user/123456
`
返回JSON格式推荐商品列表,前端渲染展示。
3.3 监控与优化
- 日志监控:通过SpringBoot Actuator暴露健康检查端点,集成ELK(Elasticsearch, Logstash, Kibana)分析推荐效果日志。
- 性能优化:
- Redis缓存推荐结果,设置TTL为6小时,减轻数据库压力。
- Spark任务调度:使用Cron定时执行离线模型训练(如每日凌晨)。
- 服务降级:当推荐服务异常时,返回预置的热门商品列表。
四、与展望
本系统通过SpringBoot快速构建推荐服务,结合Spark大数据处理能力实现可扩展的协同过滤算法,为电商平台提供了从数据采集、模型训练到在线服务的完整解决方案。系统设计注重模块化,便于后续集成深度学习模型(如神经网络协同过滤)或引入更多特征(如商品类别、用户画像)。通过容器化部署(Docker+K8s)与持续集成,可进一步提升系统弹性与运维效率,满足高并发电商场景的推荐需求。